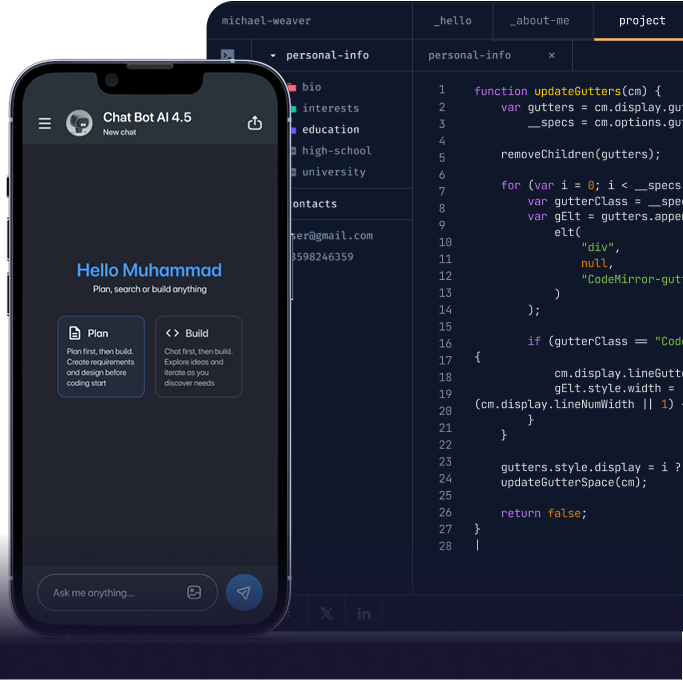
AI app development means building applications where AI features are part of the product not an add-on. Users interact with those features directly, whether through a chatbot, a search tool, or generated content. It works by connecting large language models like GPT-4 to your application through an API. The app sends a request, the model processes it, and the response is delivered back to the user in real time. The quality of that response depends on how the system is architected — what data the model has access to, how the prompt is structured, and how the backend handles the request.
This is different from machine learning development, which involves training custom models from scratch. It is also different from a basic ChatGPT integration, which only connects to the GPT API without building any product layer around it.
The result is a deployed application where AI capabilities are embedded as core product features, not bolted on as an afterthought. A knowledge base chatbot that answers from your data. Generative features that create content or summarise documents at scale. Semantic search that understands what a user means rather than matching keywords. All deployed to App Store, Google Play, or web built on your data, running on your infrastructure.

We build conversational AI chatbots that answer questions from your proprietary knowledge base. Each chatbot uses RAG architecture with Pinecone to retrieve relevant content before generating a response, so answers are grounded in your data — not in general model knowledge.
Features include multi-turn conversation memory for coherent exchanges, function calling for real-time data retrieval from your backend systems, and streaming responses so users see answers as they are generated. Chatbots are integrated into Flutter mobile apps, React Native applications, or web frontends. Firebase or Supabase handles conversation storage and session management.










We integrate generative AI features directly into your product. This covers document generation, content summarisation, personalised recommendations, image descriptions, and automated report writing all powered by GPT-4 and OpenAI API.
Each feature is built with structured prompt engineering, output validation for response quality control, and token management to keep API costs in check as usage grows. Features are delivered as modular FastAPI microservices that connect to any existing Flutter, React Native, or web application.


We build full-stack applications with AI capabilities built into the product from the start. This is not about adding an AI button to an existing app. It means designing the architecture around AI features from day one.
Applications include semantic search powered by Pinecone vector embeddings, personalisation engines that adapt to user behaviour, AI-ranked content feeds, and AI-assisted workflows. Every app is deployed to the App Store and Google Play via CI/CD. AI feature performance is monitored after launch and prompt engineering is updated based on real user data.



RAG stands for Retrieval-Augmented Generation. It is the architecture that connects your documents and knowledge base to GPT-4, so the model answers from your data rather than from its general training.
We build the full RAG pipeline document ingestion, chunking, vector embedding generation, Pinecone index management, semantic similarity search, and context injection into OpenAI API prompts. Each step matters. If the retrieval is poor, the response will be poor regardless of the model.
RAG significantly reduces AI hallucination on domain-specific queries. A chatbot built on RAG answers from what your knowledge base contains not from what the model assumes.
We provide technical consulting for businesses deciding how to approach AI development. This covers LLM selection GPT-4 versus open-source alternatives RAG versus fine-tuning decision frameworks, vector database architecture, prompt engineering strategy, AI feature scoping for MVP, and cost modelling for OpenAI API usage at scale.
The output is a clear AI product roadmap with defined architecture recommendations and build-versus-integrate decisions delivered before any development begins.
Skip the hiring process and get a senior OpenAI API and RAG architecture engineer embedded in your AI project within days. Whether you need a knowledge base chatbot, a generative AI feature added to an existing app, or a full AI-powered mobile application built from scratch, we scope and start within 48 hours.
10+ AI app developers available now · OpenAI API, GPT-4 & RAG specialists · Flutter and React Native AI apps shipped to production

AI applications deliver different value depending on the industry. A RAG-grounded knowledge base chatbot solves a different problem in healthcare than in e-commerce. A generative AI content feature serves different compliance and data requirements in fintech than in SaaS.
We build Flutter, React Native, and FastAPI-backed AI applications purpose-built for the data structures, regulatory environments, and user expectations of each sector we serve. Below are the industries we have delivered AI applications for.
We develop HIPAA-compliant healthcare apps, telemedicine platforms, EHR systems, and digital tools that enhance patient care and clinical workflows.











Every AI app project follows a structured six-phase process from AI feature scoping and RAG architecture design through prompt engineering, application build, quality assurance, and App Store or web deployment with defined deliverables and full client visibility at every stage.
We start with stakeholder workshops to define which AI capabilities deliver the most product value knowledge base chatbot, generative content features, semantic search, or workflow automation. This phase produces a full AI app specification. It covers LLM selection, RAG versus fine-tuning decision, vector database architecture, FastAPI backend design, frontend requirements, data infrastructure, and a phased delivery roadmap with fixed sprint milestones.
We audit your proprietary data and prepare it for AI integration processing documents, databases, and content into structured formats suitable for vector embedding. For RAG builds we create ingestion pipelines that chunk, embed, and index your knowledge base into Pinecone. This enables semantic search that retrieves the most relevant content for each user query. Data quality at this stage directly determines chatbot accuracy and generative feature output quality.
We design and test prompt architectures for your specific use case. This includes system prompts, context injection patterns, function calling configurations, and output validation pipelines that keep GPT-4 responses within your quality, tone, and accuracy requirements. OpenAI API integration is built into FastAPI backend microservices with token management, rate limiting, error handling, and streaming response support configured for live deployment from the first sprint.
We build the full application stack in two-week agile sprints. The frontend Flutter or React Native includes AI feature UI components, conversational chat interfaces, and real-time response streaming. The FastAPI backend handles OpenAI API and Pinecone integration. Firebase or Supabase manages user authentication, conversation history, and real-time data sync. Every sprint produces testable builds distributed via TestFlight and Firebase App Distribution.
We run a full AI app QA cycle. This covers AI response accuracy testing against your knowledge base, edge case and adversarial prompt testing, UI automation via Detox, API load testing under expected traffic volumes, and App Store and Google Play submission compliance validation. AI feature quality gates verify response accuracy, latency, and output consistency against defined benchmarks before deployment.
We deploy to App Store and Google Play via Fastlane CI/CD and configure Firebase or Supabase for live environments. After launch, we monitor AI feature performance tracking response latency, user engagement, and prompt effectiveness. Prompt engineering is updated based on real user interaction data. Response quality improves continuously after launch without requiring a new app release for every change. Regardless of the industry, every AI application we build follows this same structured process.
We start with stakeholder workshops to define which AI capabilities deliver the most product value knowledge base chatbot, generative content features, semantic search, or workflow automation. This phase produces a full AI app specification. It covers LLM selection, RAG versus fine-tuning decision, vector database architecture, FastAPI backend design, frontend requirements, data infrastructure, and a phased delivery roadmap with fixed sprint milestones.
We audit your proprietary data and prepare it for AI integration processing documents, databases, and content into structured formats suitable for vector embedding. For RAG builds we create ingestion pipelines that chunk, embed, and index your knowledge base into Pinecone. This enables semantic search that retrieves the most relevant content for each user query. Data quality at this stage directly determines chatbot accuracy and generative feature output quality.
We design and test prompt architectures for your specific use case. This includes system prompts, context injection patterns, function calling configurations, and output validation pipelines that keep GPT-4 responses within your quality, tone, and accuracy requirements. OpenAI API integration is built into FastAPI backend microservices with token management, rate limiting, error handling, and streaming response support configured for live deployment from the first sprint.
We build the full application stack in two-week agile sprints. The frontend Flutter or React Native includes AI feature UI components, conversational chat interfaces, and real-time response streaming. The FastAPI backend handles OpenAI API and Pinecone integration. Firebase or Supabase manages user authentication, conversation history, and real-time data sync. Every sprint produces testable builds distributed via TestFlight and Firebase App Distribution.
We run a full AI app QA cycle. This covers AI response accuracy testing against your knowledge base, edge case and adversarial prompt testing, UI automation via Detox, API load testing under expected traffic volumes, and App Store and Google Play submission compliance validation. AI feature quality gates verify response accuracy, latency, and output consistency against defined benchmarks before deployment.
We deploy to App Store and Google Play via Fastlane CI/CD and configure Firebase or Supabase for live environments. After launch, we monitor AI feature performance tracking response latency, user engagement, and prompt effectiveness. Prompt engineering is updated based on real user interaction data. Response quality improves continuously after launch without requiring a new app release for every change. Regardless of the industry, every AI application we build follows this same structured process.
Every AI application we build runs on a stack selected for performance and reliability in live AI deployments. OpenAI API and GPT-4 handle LLM integration. Pinecone manages vector databases and semantic search. LangChain orchestrates the RAG pipeline. Flutter or React Native delivers the mobile frontend. Python FastAPI connects every layer on the backend. Firebase or Supabase handles real-time infrastructure.
Every technology choice below maps to a specific requirement in the AI application stack:























We own the entire AI application stack OpenAI API and GPT-4 integration, Pinecone vector database architecture, LangChain RAG pipeline, FastAPI Python backend, Flutter or React Native mobile frontend, and Firebase or Supabase real-time infrastructure.
There are no handoffs between separate AI, backend, and mobile teams. One engineering team owns the problem end-to-end and is accountable for deployed AI feature performance under real user conditions not just demo accuracy.
Our RAG implementations ground every GPT-4 response in your proprietary knowledge base. We engineer document ingestion pipelines, vector embedding generation, Pinecone semantic search, and context injection into OpenAI API prompts.
The result is a chatbot or AI feature that answers from your data not from general training knowledge. Domain-specific accuracy is the difference between an AI feature users trust and one they ignore.
Prompt engineering determines AI output quality. Most development teams treat it as an afterthought. We treat it as a core engineering discipline.
We design and test prompt architectures systematically engineering system prompts, few-shot examples, output format specifications, and function calling configurations for your specific use case. After launch, we iterate prompt engineering based on real user interaction data. Response quality improves continuously without requiring app updates.
We do not build AI prototypes. We build Flutter and React Native applications with AI capabilities embedded as core features, deployed to App Store and Google Play via Fastlane CI/CD.
This includes conversational chat interfaces with real-time streaming responses, semantic search with Pinecone vector embeddings, and generative content features with output validation all built to App Store compliance requirements and deployed with CI/CD automation.
OpenAI API costs scale directly with token usage. Poorly architected AI applications generate unnecessary costs as user volume grows.
We implement token budgeting, context window management, response caching for repeated queries, and RAG retrieval optimisation to minimise API calls. Your AI features stay cost-efficient at scale without sacrificing response quality or latency.
AI features degrade differently from traditional software. Prompt effectiveness shifts as user behaviour evolves. Knowledge bases become stale. Response quality drifts without active management.
We monitor AI feature latency, response accuracy, user engagement signals, and knowledge base freshness after launch. We provide ongoing prompt engineering iteration and RAG pipeline updates to keep your AI features performing accurately long after the initial release.
Our RAG implementations ground every GPT-4 response in your proprietary knowledge base. We engineer document ingestion pipelines, vector embedding generation, Pinecone semantic search, and context injection into OpenAI API prompts.
The result is a chatbot or AI feature that answers from your data not from general training knowledge. Domain-specific accuracy is the difference between an AI feature users trust and one they ignore.
Prompt engineering determines AI output quality. Most development teams treat it as an afterthought. We treat it as a core engineering discipline.
We design and test prompt architectures systematically engineering system prompts, few-shot examples, output format specifications, and function calling configurations for your specific use case. After launch, we iterate prompt engineering based on real user interaction data. Response quality improves continuously without requiring app updates.
We do not build AI prototypes. We build Flutter and React Native applications with AI capabilities embedded as core features, deployed to App Store and Google Play via Fastlane CI/CD.
This includes conversational chat interfaces with real-time streaming responses, semantic search with Pinecone vector embeddings, and generative content features with output validation all built to App Store compliance requirements and deployed with CI/CD automation.
OpenAI API costs scale directly with token usage. Poorly architected AI applications generate unnecessary costs as user volume grows.
We implement token budgeting, context window management, response caching for repeated queries, and RAG retrieval optimisation to minimise API calls. Your AI features stay cost-efficient at scale without sacrificing response quality or latency.
AI features degrade differently from traditional software. Prompt effectiveness shifts as user behaviour evolves. Knowledge bases become stale. Response quality drifts without active management.
We monitor AI feature latency, response accuracy, user engagement signals, and knowledge base freshness after launch. We provide ongoing prompt engineering iteration and RAG pipeline updates to keep your AI features performing accurately long after the initial release.
DentaSmart is a mobile app that uses AI and 3D tech to simplify dental care, from early diagnosis to personalized treatment.
DentaSmart is a mobile app that uses AI and 3D tech to simplify dental care, from early diagnosis to personalized treatment.
From CTOs building greenfield AI-powered mobile apps to founders adding RAG chatbot integrations and generative AI features to existing products — here is what clients say about the AI engineering quality, delivery process, and application performance after working with ETechViral.
Amir Khan and his team is very responsible and works well. We have worked together and have been able to produce a good quality application. It has been easy to manage the project and they has delivered well. I would recommend others to use his services as they provide 100% perfect services.
Amir Khan and his team is very responsible and works well. We have worked together and have been able to produce a good quality application. It has been easy to manage the project and they has delivered well. I would recommend others to use his services as they provide 100% perfect services.
Amir Khan and his team is very responsible and works well. We have worked together and have been able to produce a good quality application. It has been easy to manage the project and they has delivered well. I would recommend others to use his services as they provide 100% perfect services.
There isn’t one fixed price because every project is different. The cost mostly depends on what you want to build and how complex it is. You can schedule a free consultation with our team to discuss your idea, explore options, and get a clear estimate based on your goals.
RAG stands for Retrieval-Augmented Generation. It is the architecture that connects your knowledge base to a language model, so responses are based on your data rather than on the model's general training.
Without RAG, GPT-4 answers from what it was trained on which may not reflect your products, policies, or domain. With RAG, each user query triggers a search of your knowledge base. The most relevant content is retrieved and passed to the model as context before it generates a response.
We build the full pipeline document ingestion, vector embedding generation, indexing in Pinecone, semantic similarity search, and context injection into OpenAI API prompts. RAG significantly reduces hallucination on domain-specific queries and keeps answers current as your knowledge base is updated, without requiring model fine-tuning.
Every project goes through clear stages, research, design, development, testing, and review, so nothing feels rushed or uncertain.
Quality for us starts from how we plan, not just how we code.
Yes, absolutely.
We often work with clients who already have running systems or databases. Our team can analyze your current setup and build custom integrations using APIs or other secure methods to connect new features with your existing software.
Yes, absolutely.
We often work with clients who already have running systems or databases. Our team can analyze your current setup and build custom integrations using APIs or other secure methods to connect new features with your existing software.
Yes, absolutely.
We often work with clients who already have running systems or databases. Our team can analyze your current setup and build custom integrations using APIs or other secure methods to connect new features with your existing software.
No vague proposals. No generic AI tool recommendations. Just a free 30-minute consultation with our AI app engineers, and a clear project scope with RAG architecture recommendations and AI feature roadmap delivered within 48 hours.
10+ AI App developers available now · OpenAI API · GPT-4 · Pinecone · RAG Architecture · Flutter · FastAPI · Firebase · 5+ years delivery experience
